我們擅長(zhǎng)商業(yè)策略與用戶體驗(yàn)的完美結(jié)合。
歡迎瀏覽我們的案例。
我認(rèn)為 Yann LeCun 等人于 1989 年發(fā)表的論文「反向傳播應(yīng)用于手寫(xiě)郵政編碼識(shí)別」(Backpropagation Applied to Handwritten Zip Code Recognition),具有相當(dāng)重要的歷史意義,因?yàn)閾?jù)我所知,這是最早用反向傳播機(jī)制端到端訓(xùn)練的神經(jīng)網(wǎng)絡(luò)在現(xiàn)實(shí)生活中的應(yīng)用。
除了其使用的微型數(shù)據(jù)集(7291 個(gè) 16x16 的灰度數(shù)字圖像)和微型神經(jīng)網(wǎng)絡(luò)(僅 1000 個(gè)神經(jīng)元)顯得落伍之外,在 33 年后的今天,這篇論文讀來(lái)仍然十分新穎——它展示了一個(gè)數(shù)據(jù)集,描述了神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)、損失函數(shù)、優(yōu)化器,并報(bào)告了在訓(xùn)練集和測(cè)試集上實(shí)驗(yàn)得到的錯(cuò)誤率。
除了時(shí)光已流逝 33 年,這篇文章仍是一篇標(biāo)準(zhǔn)的深度學(xué)習(xí)論文。因此,我此次復(fù)現(xiàn)這篇論文,一是為了好玩,二是將這次練習(xí)作為一個(gè)案例來(lái)研究深度學(xué)習(xí)進(jìn)展的本質(zhì)。
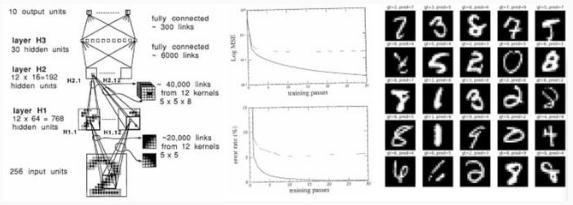
實(shí)施細(xì)節(jié)
我試著盡可能與這篇論文保持一致,并用 PyTorch 復(fù)現(xiàn)了 GitHub repo 上 karpathy/lecun1989-repro 中的所有內(nèi)容。
最初的網(wǎng)絡(luò)部署在 Lisp 上,使用 Bottou 和 LeCun 1988 年發(fā)表的「backpropagation simulator SN(后來(lái)命名為 Lush)」。
這篇論文是用法語(yǔ)寫(xiě)的,所以我沒(méi)有更好地理解它,但從結(jié)構(gòu)上來(lái)看,你可以使用更高級(jí)的 API 來(lái)構(gòu)造神經(jīng)網(wǎng)絡(luò),就像你今天在 PyTorch 上搭建各式各樣的項(xiàng)目那樣。
作為軟件設(shè)計(jì)的簡(jiǎn)要說(shuō)明,現(xiàn)代程序庫(kù)采用了一種分為 3 部分的設(shè)計(jì):
1)一個(gè)高速(C/CUDA)通用張量庫(kù),能在多維張量上實(shí)現(xiàn)基本的數(shù)學(xué)運(yùn)算;
2)一個(gè)自動(dòng)求導(dǎo)引擎,能跟蹤正向計(jì)算特征,并能提供反向傳播操作;
3)可編程(Python)的深度學(xué)習(xí)編碼器,高級(jí)的 API,需要包含常見(jiàn)的深度學(xué)習(xí)操作,比如構(gòu)建層、架構(gòu)、提供優(yōu)化器、損失函數(shù)等。
訓(xùn)練細(xì)節(jié)
在訓(xùn)練過(guò)程中,我們必須在有 7291 個(gè)示例的訓(xùn)練集上訓(xùn)練 23 個(gè)周期,總共向神經(jīng)網(wǎng)絡(luò)傳送了 167693 次數(shù)據(jù)(包含樣本和標(biāo)簽)。最初的網(wǎng)絡(luò)在 SUN-4/260 工作站上訓(xùn)練了 3 天。
我在我的 MacBook Air(M1)CPU 上運(yùn)行了我的實(shí)現(xiàn),并在大約 90 秒的時(shí)間內(nèi)完成了運(yùn)行(約 3000 倍的顯著提速)。
我的 conda 設(shè)置為使用本機(jī) AMD64 版本,而不是 Rosetta 仿真。如果 Pytorch 支持 M 1(包括 GPU 和 NPU)的全部功能,加速可能會(huì)更顯著,但這似乎仍在開(kāi)發(fā)中。
我還天真地嘗試在一張 A100 GPU 上運(yùn)行代碼,但實(shí)際上訓(xùn)練速度更慢了,很可能是因?yàn)榫W(wǎng)絡(luò)太小了(4 個(gè)卷積層,最多 12 個(gè)通道,總共 9760 個(gè)參數(shù),64 K 位址量,1 K 激活值),SGD 每次只能使用一個(gè)樣本。
這就是說(shuō),如果真的想用現(xiàn)代硬件(A100)和軟件基礎(chǔ)設(shè)施(CUDA、PyTorch)解決這個(gè)問(wèn)題,我們需要用每個(gè)樣本的 SGD 過(guò)程來(lái)交換完整的批量訓(xùn)練,以最大限度地提高 GPU 利用率,并很可能實(shí)現(xiàn)另一個(gè)約 100 倍的訓(xùn)練耗時(shí)提速。
復(fù)現(xiàn) 1989 年的表現(xiàn)
原論文展示的結(jié)果如下:
eval: split train. loss 2.5e-3. error 0.14%. misses: 10
eval: split test . loss 1.8e-2. error 5.00%. misses: 102
而我的復(fù)現(xiàn)代碼在同時(shí)期的表現(xiàn)如下:
eval: split train. loss 4.073383e-03. error 0.62%. misses: 45
eval: split test . loss 2.838382e-02. error 4.09%. misses: 82
由此可見(jiàn),我只能粗略地再現(xiàn)這些結(jié)果,卻不能做到完全一樣。可悲的是,很可能永遠(yuǎn)無(wú)法進(jìn)行精確復(fù)現(xiàn)了,因?yàn)槲艺J(rèn)為原始數(shù)據(jù)集已經(jīng)被遺棄在了時(shí)間的長(zhǎng)河中。
相反,我不得不使用更大的 MNIST 數(shù)據(jù)集(哈哈,我從沒(méi)想過(guò)我會(huì)用「大」來(lái)形容它)來(lái)模擬它,取其 28x28 位,通過(guò)雙線性插值將其縮小到 16x16 像素,并隨機(jī)地從中提取合理數(shù)量的訓(xùn)練集和測(cè)試集樣本。
但我相信還有其他罪魁禍?zhǔn)住@纾@篇論文對(duì)權(quán)重初始化方案的描述有點(diǎn)過(guò)于抽象,我懷疑 PDF 文件中存在一些格式錯(cuò)誤,例如,刪除點(diǎn)「.」讓「2.5」看起來(lái)像「2 5」,并且有可能(我想是吧?)刪除了平方根。
例如,我們被告知權(quán)重初始值是從均勻的「2 4/F」中提取的,其中 F 是扇入,但我猜這肯定是(我猜的)指「2.4/sqrt(F)」,其中 sqrt 有助于保持輸出的標(biāo)準(zhǔn)偏差。
網(wǎng)絡(luò)的 H1 層和 H2 層之間的特定稀疏連接結(jié)構(gòu)也被忽略了,論文只是說(shuō)它是“根據(jù)一個(gè)在這里不會(huì)被討論的方案選擇的”,所以我不得不在這里做出一些合理的猜測(cè),比如使用重疊塊稀疏結(jié)構(gòu)。
論文還聲稱使用了 tanh 非線性,但我想這實(shí)際上可能是映射 ntanh(1)=1 的「標(biāo)準(zhǔn)化 tanh」,并可能添加了一個(gè)按比例縮小的跳躍連接,這是在當(dāng)時(shí)很流行的操作,以確保 tanh 平滑的尾部至少有一點(diǎn)梯度。
最后,本文使用了「牛頓算法的一個(gè)特殊版本,它使用了 Hessian 的正對(duì)角近似值」,但我只使用了 SGD,因?yàn)樗浅:?jiǎn)單,更何況根據(jù)本文,「人們認(rèn)為該算法不會(huì)帶來(lái)學(xué)習(xí)速度的巨大提高」。
坐上時(shí)光車「作弊」
這是我最喜歡的部分。
想一下,相比于 1989,我們已經(jīng)在未來(lái)生活了 33 年,這時(shí)的深度學(xué)習(xí)是一個(gè)非常火爆的研究領(lǐng)域。 利用我們的現(xiàn)代理解和 33 年來(lái)的研發(fā)技術(shù)積累,我們能在原有成果的基礎(chǔ)上提高多少?
我最初的結(jié)果是:
eval: split train. loss 4.073383e-03. error 0.62%. misses: 45 eval: split test . loss 2.838382e-02. error 4.09%. misses: 82
歸到目標(biāo) -1(負(fù)類)或 +1(正類)的任務(wù),輸出神經(jīng)元同樣也具有 tanh 非線性。 所以我刪除了輸出層上的 tanh 以獲得類別 logit,并在標(biāo)準(zhǔn)(多類)交叉熵?fù)p失函數(shù)中交換。 這一變化極大地改善了訓(xùn)練錯(cuò)誤,在訓(xùn)練集上直接過(guò)擬合了,結(jié)果如下:
eval: split train. loss 9.536698e-06. error 0.00%. misses: 0 eval: split test . loss 9.536698e-06. error 4.38%. misses: 87
其次,根據(jù)我的經(jīng)驗(yàn),一個(gè)經(jīng)過(guò)微調(diào)的 SGD 可以很好地工作,但現(xiàn)代的 Adam 優(yōu)化器(當(dāng)然,學(xué)習(xí)率為 3e-4)幾乎總是作為一個(gè)強(qiáng)大的 baseline,幾乎不需要任何調(diào)整。 因此,為了提高我對(duì)優(yōu)化不會(huì)影響性能的信心,我選擇了使用學(xué)習(xí)率為 3e-4 的 AdamW,并在訓(xùn)練過(guò)程中逐步將其降至 1e-4,結(jié)果如下:
eval: split train. loss 0.000000e+00. error 0.00%. misses: 0 eval: split test . loss 0.000000e+00. error 3.59%. misses: 72
由于仍然出現(xiàn)了嚴(yán)重的過(guò)度擬合,我隨后介紹了一種簡(jiǎn)單的數(shù)據(jù)增強(qiáng)策略,將輸入圖像水平或垂直移動(dòng)最多 1 個(gè)像素。 然而,由于這模擬了數(shù)據(jù)集大小的增加,我還必須將訓(xùn)練周期數(shù)數(shù)從 23 次增加到 60 次(我已經(jīng)驗(yàn)證過(guò)在原始設(shè)置中單純地增加通過(guò)次數(shù)并不能顯著改善結(jié)果):
eval: split train. loss 8.780676e-04. error 1.70%. misses: 123 eval: split test . loss 8.780676e-04. error 2.19%. misses: 43
數(shù)據(jù)增強(qiáng)是一個(gè)相當(dāng)簡(jiǎn)單且非常標(biāo)準(zhǔn)的概念,用于克服過(guò)度擬合,但我在 1989 年的論文中沒(méi)有找到它,也許它是一個(gè) 1989 年后才有的創(chuàng)新(我猜的)。
由于我們?nèi)匀挥悬c(diǎn)過(guò)擬合,我在工具箱中找到了另一個(gè)現(xiàn)代工具,Dropout。 我在參數(shù)最多的層(H 3)前加了一個(gè) 0.25 的弱衰減。
因?yàn)?dropout 將激活設(shè)置為零,所以將其與激活范圍為 [-1, 1] 的 tanh 一起使用沒(méi)有多大意義,所以我也將所有非線性替換為更簡(jiǎn)單的 ReLU 激活函數(shù)。 因?yàn)?dropout 在訓(xùn)練中會(huì)帶來(lái)更多的噪音,我們還必須訓(xùn)練更長(zhǎng)的時(shí)間,增加至最多 80 個(gè)訓(xùn)練周期,但結(jié)果卻變得十分喜人:
eval: split train. loss 2.601336e-03. error 1.47%. misses: 106 eval: split test . loss 2.601336e-03. error 1.59%. misses: 32
我驗(yàn)證了在原來(lái)的網(wǎng)絡(luò)中僅僅交換 tanh->relu 并沒(méi)有帶來(lái)實(shí)質(zhì)性的收益,所以這里的大部分改進(jìn)都來(lái)自于增加了 dropout。
總之,如果我能時(shí)光旅行到 1989 年,我將能夠減少大約 60% 的錯(cuò)誤率,使我們從約 80 個(gè)錯(cuò)誤減少到約 30 個(gè)錯(cuò)誤,測(cè)試集的總體錯(cuò)誤率約為 1.5%。
這并不是完全沒(méi)有代價(jià)的,因?yàn)槲覀冞€將訓(xùn)練時(shí)間增加了近 4 倍,這將使 1989 年的訓(xùn)練時(shí)間從 3 天增加到近 12 天。但推理速度不會(huì)受到影響。
剩下的測(cè)試失敗樣本如下所示:

更進(jìn)一步
然而,在替換 MSE->Softmax,SGD->AdamW,添加數(shù)據(jù)增強(qiáng),dropout,交換 tanh→relu 之后,我開(kāi)始逐漸減少依賴觸手可得的技巧。
我嘗試了更多的方法(例如權(quán)重標(biāo)準(zhǔn)化),但沒(méi)有得到更好的結(jié)果。 我還嘗試將 Visual Transformer(ViT)小型化為「 micro-ViT」,大致在參數(shù)量和計(jì)算量上與之前相符,但無(wú)法仿真 convnet 的性能。
當(dāng)然,在過(guò)去的 33 年里,我們還研究出了許多其他創(chuàng)新,但其中許多創(chuàng)新(例如,殘差連接,層/批次標(biāo)準(zhǔn)化)只適用于更大的模型,并且大多有助于穩(wěn)定大規(guī)模優(yōu)化。
在這一點(diǎn)上,進(jìn)一步的收益可能來(lái)自網(wǎng)絡(luò)規(guī)模的擴(kuò)大,但這會(huì)增加測(cè)試的推斷時(shí)間。
用數(shù)據(jù)「作弊」
另一種提高性能的方法是擴(kuò)大數(shù)據(jù)集的規(guī)模,盡管完成數(shù)據(jù)標(biāo)注需要一些成本。
我們?cè)谧畛醯?baseline(再次作為消融參考)上測(cè)試結(jié)果是:
eval: split train. loss 4.073383e-03. error 0.62%. misses: 45 eval: split test . loss 2.838382e-02. error 4.09%. misses: 82
讓 baseline 訓(xùn)練 100 個(gè)周期,這已經(jīng)表明僅僅增加數(shù)據(jù)就能提高性能:
eval: split train. loss 1.305315e-02. error 2.03%. misses: 60 eval: split test . loss 1.943992e-02. error 2.74%. misses: 54
但進(jìn)一步將其與當(dāng)代知識(shí)的創(chuàng)新(如前一節(jié)所述)結(jié)合在一起,將帶來(lái)迄今為止最好的表現(xiàn):
eval: split train. loss 3.238392e-04. error 1.07%. misses: 31 eval: split test . loss 3.238392e-04. error 1.25%. misses: 24
總而言之,在 1989 年簡(jiǎn)單地?cái)U(kuò)展數(shù)據(jù)集將是提高系統(tǒng)性能的有效方法,且不需要犧牲推理時(shí)間。
反思
讓我們總結(jié)一下我們?cè)?2022 年時(shí),作為一名時(shí)間旅行者考察 1989 年最先進(jìn)的深度學(xué)習(xí)技術(shù)時(shí)所學(xué)到的:
首先,33 年來(lái)宏觀層面上沒(méi)有太大變化。我們?nèi)栽诮⒂缮窠?jīng)元層組成的可微神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),并通過(guò)反向傳播和隨機(jī)梯度下降對(duì)其進(jìn)行端到端優(yōu)化。所有的東西讀起來(lái)都非常熟悉,只是 1989 時(shí)它們的體量比較小。
按照今天的標(biāo)準(zhǔn),1989 年的數(shù)據(jù)集就是一個(gè)「嬰兒」:訓(xùn)練集只有 7291 個(gè) 16x16 的灰度圖像。今天的視覺(jué)數(shù)據(jù)集通常包含數(shù)億張來(lái)自網(wǎng)絡(luò)的高分辨率彩色圖像(例如,谷歌有 JFT-300M,OpenAI CLIP 是在 400M 的數(shù)據(jù)集上訓(xùn)練的),但仍會(huì)增長(zhǎng)到幾十億。這大約是此前每幅圖像約一千倍的像素信息(384*384*3/(16*16))乘以十萬(wàn)倍的圖像數(shù)(1e9/1e4),輸入的像素?cái)?shù)據(jù)的差距約為一億倍。
那時(shí)的神經(jīng)網(wǎng)絡(luò)也是一個(gè)「嬰兒」:這個(gè) 1989 年的網(wǎng)絡(luò)有大約 9760 個(gè)參數(shù)、64 K 個(gè)位址和 1 K 個(gè)激活值。現(xiàn)代(視覺(jué))神經(jīng)網(wǎng)絡(luò)的規(guī)模通常有幾十億個(gè)小參數(shù)(1000000X)和 O(~1e12)個(gè)位址數(shù)(~1000000X),而自然語(yǔ)言模型甚至可以達(dá)到數(shù)萬(wàn)億級(jí)別的參數(shù)量。
最先進(jìn)的分類器花了 3 天時(shí)間在工作站上訓(xùn)練,而現(xiàn)在在我的無(wú)風(fēng)扇筆記本電腦上訓(xùn)練只需 90 秒(3000 倍原始提速),通過(guò)切換到全批量?jī)?yōu)化并使用 GPU,很可能能進(jìn)一步獲得 100 倍的提升。
事實(shí)上,我能夠根據(jù)現(xiàn)代的技術(shù)創(chuàng)新調(diào)整模型,比如使用數(shù)據(jù)增強(qiáng),更好的損失函數(shù)和優(yōu)化器,以將錯(cuò)誤率降低 60%,同時(shí)保持?jǐn)?shù)據(jù)集和模型的測(cè)試時(shí)間不變。
僅通過(guò)增大數(shù)據(jù)集就可以獲得適度的收益。
進(jìn)一步的顯著收益可能來(lái)自更大的模型,這將需要更多的計(jì)算成本和額外的研發(fā),以幫助在不斷擴(kuò)大的規(guī)模上穩(wěn)定訓(xùn)練。值得一提的是,如果我被傳送到 1989 年,我最終會(huì)在沒(méi)有更強(qiáng)大計(jì)算機(jī)的情況下,使模型達(dá)到改進(jìn)能力的上限。
假設(shè)這個(gè)練習(xí)的收獲在時(shí)間維度上保持不變。2022 年的深度學(xué)習(xí)意味著什么?2055 年的時(shí)間旅行者會(huì)如何看待當(dāng)前網(wǎng)絡(luò)的性能?
2055 年的神經(jīng)網(wǎng)絡(luò)在宏觀層面上與 2022 年的神經(jīng)網(wǎng)絡(luò)基本相同,只是更大。
我們今天的數(shù)據(jù)集和模型看起來(lái)像個(gè)笑話。兩者都在大約上千億倍大于當(dāng)前數(shù)據(jù)集和模型。
我們可以在個(gè)人電腦設(shè)備上用大約一分鐘的時(shí)間來(lái)訓(xùn)練 2022 年最先進(jìn)的模型,這將成為一個(gè)有趣的周末項(xiàng)目。
今天的模型并不是最優(yōu)的,只要改變模型的一些細(xì)節(jié),損失函數(shù),數(shù)據(jù)增強(qiáng)或優(yōu)化器,我們就可以將誤差減半。
我們的數(shù)據(jù)集太小,僅通過(guò)擴(kuò)大數(shù)據(jù)集的規(guī)模就可以獲得適度的收益。
如果不升級(jí)運(yùn)算設(shè)備,并投資一些研發(fā),以有效地訓(xùn)練如此規(guī)模的模型,就不可能取得進(jìn)一步的收益。
但我想說(shuō)的最重要的趨勢(shì)是, 在某些目標(biāo)任務(wù)(如數(shù)字識(shí)別)上從頭開(kāi)始訓(xùn)練一個(gè)神經(jīng)網(wǎng)絡(luò)的整個(gè)過(guò)程由于過(guò)于精細(xì)化而很快變得過(guò)時(shí),特別是隨著 GPT 等基礎(chǔ)模型的出現(xiàn)。
這些基礎(chǔ)模型只由少數(shù)具有大量計(jì)算資源的機(jī)構(gòu)來(lái)訓(xùn)練,并且大多數(shù)應(yīng)用是通過(guò)輕量級(jí)的微調(diào)網(wǎng)絡(luò),快速部署工程,數(shù)據(jù)清洗,模型蒸餾,用專用的推理網(wǎng)絡(luò)來(lái)實(shí)現(xiàn)的。
我認(rèn)為,我們應(yīng)該期待這一趨勢(shì)愈發(fā)蓬勃,而且也已經(jīng)確實(shí)如此。 在最極端的推斷中,你根本不會(huì)想訓(xùn)練任何神經(jīng)網(wǎng)絡(luò)。
在 2055 年,你將要求一個(gè)千億大小的神經(jīng)網(wǎng)絡(luò)超強(qiáng)大腦通過(guò)用英語(yǔ)說(shuō)話(或思考)來(lái)執(zhí)行一些任務(wù)。
如果你的要求足夠清晰,它會(huì)很樂(lè)意執(zhí)行的。當(dāng)然,你也可以自己訓(xùn)練神經(jīng)網(wǎng)絡(luò)……但你還有什么訓(xùn)練的必要呢?
(邯鄲小程序開(kāi)發(fā))


小米應(yīng)用商店發(fā)布消息稱 持續(xù)開(kāi)展“APP 侵害用戶權(quán)益治理”系列行動(dòng) 11:37:04
騰訊云與CSIG成立政企業(yè)務(wù)線 加速數(shù)字技術(shù)在實(shí)體經(jīng)濟(jì)中的落地和應(yīng)用 11:34:49
樂(lè)視回應(yīng)還有400多人 期待新的朋友加入 11:29:25
亞馬遜表示 公司正在將其智能購(gòu)物車擴(kuò)展到馬薩諸塞州的一家全食店 10:18:04
三星在元宇宙平臺(tái)推出游戲 玩家可收集原材料制作三星產(chǎn)品 09:57:29
特斯拉加州San Mateo裁減229名員工 永久關(guān)閉該地區(qū)分公司 09:53:13